The lazyeval package is a toolset for performing nonstandard evaluation in R. Nonstandard evaluation refers to any situation where something special happens with how user input or code is evaluated.
For example, the library() function doesn’t evaluate variables. In the example below, I try to trick library() into loading a fake package called evil_package by assigning to the package name lazyeval. In other words, we have the expression lazyeval and its value is "evil_package".
But this gambit doesn’t work because library() did something special: It didn’t evaluate the expression lazyeval. In the source code of library(), there is a line package <- as.character(substitute(package)) which replaces the value of package with a character version of the expression that the user wrote.
That’s a simple example of nonstandard evaluation, but it’s pervasive. It’s why you never have to quote column names in dplyr or ggplot2. In this post, I present some recent examples where I decided to use the lazyeval package to do something nonstandard. These examples are straight out of the lazyeval vignette in terms of complexity, but that’s fine. We all have to start somewhere.
Capturing expressions
Plot titles. While reading the book Machine Learning For Hackers, I wanted to plot random numbers generated by probability distributions discussed by the book. I used the lazyeval::expr_text() function to capture the command used to generate the numbers and write it as the title of the plot.
library(dplyr, warn.conflicts = FALSE)
library(ggplot2)
plot_dist <- function(xs) {
data <- tibble(x = xs)
ggplot(data) +
aes(x = x) +
geom_density() +
ggtitle(lazyeval::expr_text(xs))
}
plot_dist(rcauchy(n = 250, location = 0, scale = 1))
plot_dist()plot_dist(rgamma(n = 25000, shape = 5, rate = .5))
plot_dist()plot_dist(rexp(n = 25000, rate = .5))
plot_dist()Less fussy warning messages. I recently inherited some code where there were custom warning messages based on the input. The code threw a warning whenever a duplicate participant ID was found in a survey. It went something like this:
# some dummy data
study1 <- tibble(
id = c(1, 2, 3, 4),
response = c("b", "c", "a", "b")
)
study2 <- tibble(
id = c(1, 2, 2, 3, 1),
response = c("a", "a", "a", "b", "c")
)
if (anyDuplicated(study1$id)) {
warning("Duplicate IDs found in Study1", call. = FALSE)
}
if (anyDuplicated(study2$id)) {
warning("Duplicate IDs found in Study2", call. = FALSE)
}
#> Warning: Duplicate IDs found in Study2To extend this code to a new study, one would just copy-and-paste and update the if statement’s condition and warning messages. Like so:
study3 <- tibble(
id = c(1, 2, 3, 2),
response = c("b", "c", "a", "b")
)
if (anyDuplicated(study3$id)) {
warning("Duplicate IDs found in Study2", call. = FALSE)
}
#> Warning: Duplicate IDs found in Study2Wait, that’s not right! I forgot to update the warning message…
This setup is too brittle for me, so I abstracted the procedure into a function. First, I wrote a helper function to print out duplicates elements in a vector. This helper will let us make the warning message a little more informative.
Next, I wrote a function to issue the warnings. I used lazyeval::expr_label() convert the user-inputted expression into a string wrapped in backticks.
# Print a warning if duplicates are found in a vector
warn_duplicates <- function(xs) {
if (anyDuplicated(xs)) {
# Get what the user wrote for the xs argument
actual_xs <- lazyeval::expr_label(xs)
msg <- paste0(
"Duplicate entries in ", actual_xs, ": ", print_duplicates(xs)
)
warning(msg, call. = FALSE)
}
invisible(NULL)
}
warn_duplicates(study1$id)
warn_duplicates(study2$id)
#> Warning: Duplicate entries in `study2$id`: 1, 2
warn_duplicates(study3$id)
#> Warning: Duplicate entries in `study3$id`: 2The advantage of this approach is that the warning is a generic message that can work on any input. But in a funny way, the warning is also customized for the input because it includes the input printed verbatim.
An aside: In plotting, I used lazyeval::expr_text(), but here I used lazyeval::expr_label(). The two differ slightly. Namely, expr_label() surrounds the captured expression with backticks to indicate that expression is code:
lazyeval::expr_text(stop())
#> [1] "stop()"
lazyeval::expr_label(stop())
#> [1] "`stop()`"
# 2021-01-05: rlang requires you to separate the quoting from the quoting
rlang::quo_text(quote(stop()))
#> [1] "stop()"
rlang::quo_label(quote(stop()))
#> [1] "`stop()`"
rlang::quo_text(rlang::quo(stop()))
#> [1] "stop()"
rlang::quo_label(rlang::quo(stop()))
#> [1] "`stop()`"Asking questions about a posterior distribution
I fit regression models with RStanARM. It lets me fit Bayesian models in Stan by writing conventional R modeling code. (Btw, I’m giving a tutorial on RStanARM in a month.)
Here’s a model about some famous flowers.
library(rstanarm)
#> Loading required package: Rcpp
#> Warning: package 'Rcpp' was built under R version 4.3.1
#> This is rstanarm version 2.21.4
#> - See https://mc-stan.org/rstanarm/articles/priors for changes to default priors!
#> - Default priors may change, so it's safest to specify priors, even if equivalent to the defaults.
#> - For execution on a local, multicore CPU with excess RAM we recommend calling
#> options(mc.cores = parallel::detectCores())
model <- stan_glm(
Petal.Width ~ Petal.Length * Species,
data = iris,
family = gaussian(),
prior = normal(0, 1),
seed = "20230718"
)Here’s the essential relationship being explored.
ggplot(iris) +
aes(x = Petal.Length, y = Petal.Width, color = Species) +
geom_point() +
stat_smooth(method = "lm")
#> `geom_smooth()` using formula = 'y ~ x'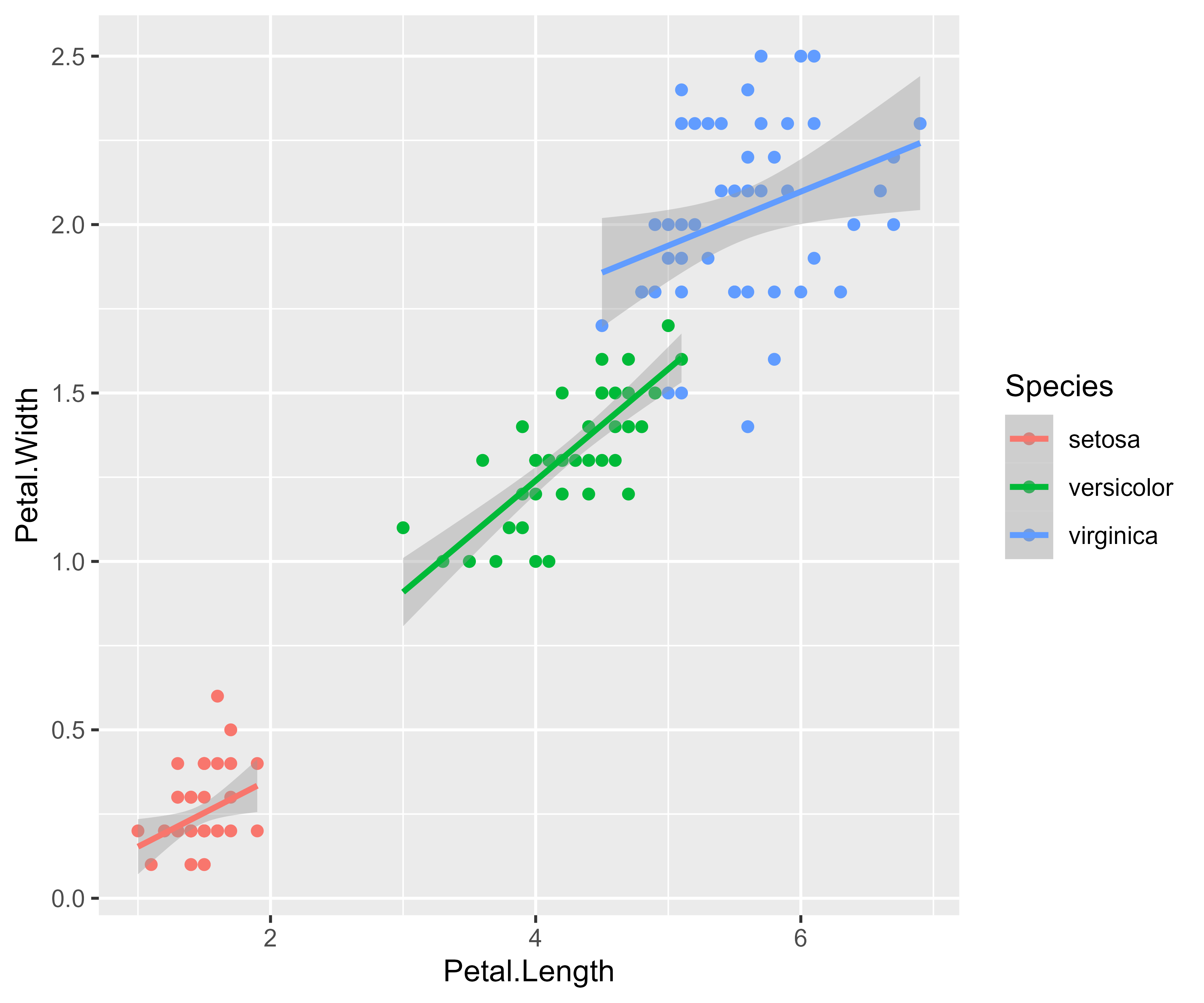
The model gives me 4000 samples from the posterior distribution of the model.
summary(model)
#>
#> Model Info:
#> function: stan_glm
#> family: gaussian [identity]
#> formula: Petal.Width ~ Petal.Length * Species
#> algorithm: sampling
#> sample: 4000 (posterior sample size)
#> priors: see help('prior_summary')
#> observations: 150
#> predictors: 6
#>
#> Estimates:
#> mean sd 10% 50% 90%
#> (Intercept) 0.0 0.2 -0.3 0.0 0.3
#> Petal.Length 0.2 0.1 0.0 0.2 0.3
#> Speciesversicolor -0.1 0.3 -0.5 -0.1 0.3
#> Speciesvirginica 1.1 0.3 0.7 1.1 1.5
#> Petal.Length:Speciesversicolor 0.2 0.1 0.0 0.2 0.4
#> Petal.Length:Speciesvirginica 0.0 0.1 -0.2 0.0 0.2
#> sigma 0.2 0.0 0.2 0.2 0.2
#>
#> Fit Diagnostics:
#> mean sd 10% 50% 90%
#> mean_PPD 1.2 0.0 1.2 1.2 1.2
#>
#> The mean_ppd is the sample average posterior predictive distribution of the outcome variable (for details see help('summary.stanreg')).
#>
#> MCMC diagnostics
#> mcse Rhat n_eff
#> (Intercept) 0.0 1.0 858
#> Petal.Length 0.0 1.0 862
#> Speciesversicolor 0.0 1.0 1147
#> Speciesvirginica 0.0 1.0 1165
#> Petal.Length:Speciesversicolor 0.0 1.0 839
#> Petal.Length:Speciesvirginica 0.0 1.0 829
#> sigma 0.0 1.0 2756
#> mean_PPD 0.0 1.0 3166
#> log-posterior 0.0 1.0 1394
#>
#> For each parameter, mcse is Monte Carlo standard error, n_eff is a crude measure of effective sample size, and Rhat is the potential scale reduction factor on split chains (at convergence Rhat=1).At the 2.5% quantile, the Petal.Length effect looks like zero or less than zero. What proportion of the Petal.Length effects (for setosa flowers) is positive?
To answer questions like this one in a convenient way, I wrote a function that takes a boolean expression about a model’s parameters and evaluates it inside of the data-frame summary of the model posterior distribution. lazyeval::f_eval() does the nonstandard evaluation: It evaluates an expression captured by a formula like ~ 0 < Petal.Length inside of a list or data-frame. (Note that the mean of a logical vector is the proportion of the elements that are true.)
# Get proportion of posterior samples satisfying some inequality
posterior_proportion_ <- function(model, inequality) {
draws <- as.data.frame(model)
mean(lazyeval::f_eval(inequality, data = draws))
}
posterior_proportion_(model, ~ 0 < Petal.Length)
#> [1] 0.87675But all those tildes… The final underscore in posterior_proportion_() follows a convention for distinguishing between nonstandard evaluation functions that require formulas and those that do not. In the dplyr package, for example, there is select_()/select()/, mutate_()/mutate(), and so on. We can do the formula-free form of this function by using lazyeval::f_capture() to capture the input expression as a formula. We then hand that off to the version of the function that takes a formula.
posterior_proportion <- function(model, expr) {
posterior_proportion_(model, lazyeval::f_capture(expr))
}
posterior_proportion(model, 0 < Petal.Length)
#> [1] 0.87675Here’s another question: What proportion of the posterior of the Petal.Length effect for virginica flowers is positive? In classical models, we would change the reference level for the categorical variable, refit the model, and check the significance. But I don’t want to refit this model because that would repeat the MCMC sampling. (It takes about 30 seconds to fit this model after all!) I’ll just ask the model for the sum of Petal.Length and Petal.Length:Speciesversicolor effects. That will give me the estimated Petal.Length effect but adjusted for the versicolor species.
posterior_proportion(model, 0 < Petal.Length + `Petal.Length:Speciesversicolor`)
#> [1] 1
posterior_proportion(model, 0 < Petal.Length + `Petal.Length:Speciesvirginica`)
#> [1] 1(The backticks around Petal.Length:Speciesversicolor here prevent the : symbol from being evaluated as an operator.)